
Au 3.1 Speech emotion recognition
- ashvineek9
- Oct 2, 2021
- 2 min read
Updated: Oct 26, 2021

Speech emotion recognition (SER) is a vital component in human-computer interaction applications. Speech is unevenly time distributed data. Attention is going to play a significant role in extracting required features. There is a lot of research done on Automatic emotion recognition (AER). A few applications of AER are, monitoring the stress of plane pilots, enhancing players' experience with video games, and mental health care with a chatbot. In mental health care, the data is physiological signals such as EEG, heart rate variability, as well as a fusion of multiple modalities. A real-time implementation of AER has been challenging. It is because of less computing power, fast processing times, and a high degree of accuracy needed.


The speech is converted to the numerical vector on which the feature extraction is performed. Essential information is captured during the feature extraction. Feature extraction and classification are two important components of AER. Features are Mel-frequency cepstral coefficients (MFCCs), and linear prediction cepstral coefficients (LPCC). A few more features are short-time energy, fundamental frequency (F0), and formats. Gaussian mixture model (GMM), hidden Markov model (HMM), and support vector machine (SVM) are a few classifications models used for SER. Classification is also performed using a deep learning model. Such as multi-layer perception (MLP), extreme learning machine (ELM), convolutional neural networks (CNN), residual neural networks (ResNets), recurrent neural networks (RNNs), and auto-encoder (AE). Long short-term memory (LSTM), and gated recurrent unit (GNU) along with attention mechanism (AM) are widely used models for AER.




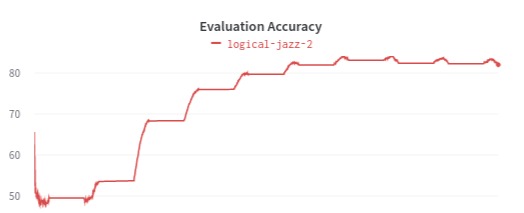

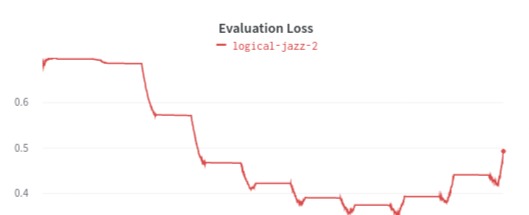

The evaluation metrics used are precision, multi-class recall, weighted accuracy, and F1 score. A multi-class recall is referred to as unweighted average recall (UAR). UAR corresponds to unweighted accuracy (UA). It is computed as the average over individual class accuracies. Weighted accuracy or weighted average recall (WAR) is computed as the class-specific recalls weighted by the number of per-class instances. Weighted accuracy can be considered as an accuracy. Two more metrics can be used to find a correlation coefficient for regression. These two are Pearson’s correlation coefficient and Concordance Correlation Coefficient. Pearson’s correlation coefficient measures the correlation between the true and predicted values. The concordance Correlation Coefficient examines the relationship between the true and predicted values. Cross-validation can be used to improve the performance of SER.
Few deep learning techniques that can improve classification performance are data augmentation, transfer learning, and cross-domain recognition (the attention mechanism). Few problems in the SER data can be background noise and reverberation or unbalanced emotional categories. There are six basics also known as the big six emotional categories. They are anger, disgust, fear, happiness, sadness, surprise, and neutrality. If SER is considered a regression problem, the emotions are mapped to continuous values representing the degree of emotional arousal, valence, and dominance. Valence is a continuum ranging from unhappiness to happiness, arousal ranges from sleepiness to excitement, dominance is in a range from submissiveness to dominance (e.g., control, influence). In the case of speech emotion recognition, the focus is on the speaker and his emotional state. Extract substantial information from the feature set while discarding redundant values. This will help to optimize the time complexity while maintaining similar accuracy.
Reference:
Rethinking environmental sound classification using ..., https://link.springer.com/article/10.1007/s00521-021-06091-7.
https://wandb.ai/sauravmaheshkar/LSTM-PyTorch/reports/How-to-Use-LSTMs-in-PyTorch--VmlldzoxMDA2NTA5?galleryTag=

Comments